InteractiveGraph






InteractiveGraph provides a web-based interactive operating framwork for large graph data, which may come from a GSON file, or an online Neo4j graph database.
InteractiveGraph also provides three applications built on the framework: GraphNavigator, GraphExplorer and RelFinder.
GraphNavigator: online demo https://grapheco.github.io/InteractiveGraph/dist/examples/example1.html

GraphExplorer: online demo
https://grapheco.github.io/InteractiveGraph/dist/examples/example2.html

RelFinder: online demo https://grapheco.github.io/InteractiveGraph/dist/examples/example3.html

OpenWebFlow




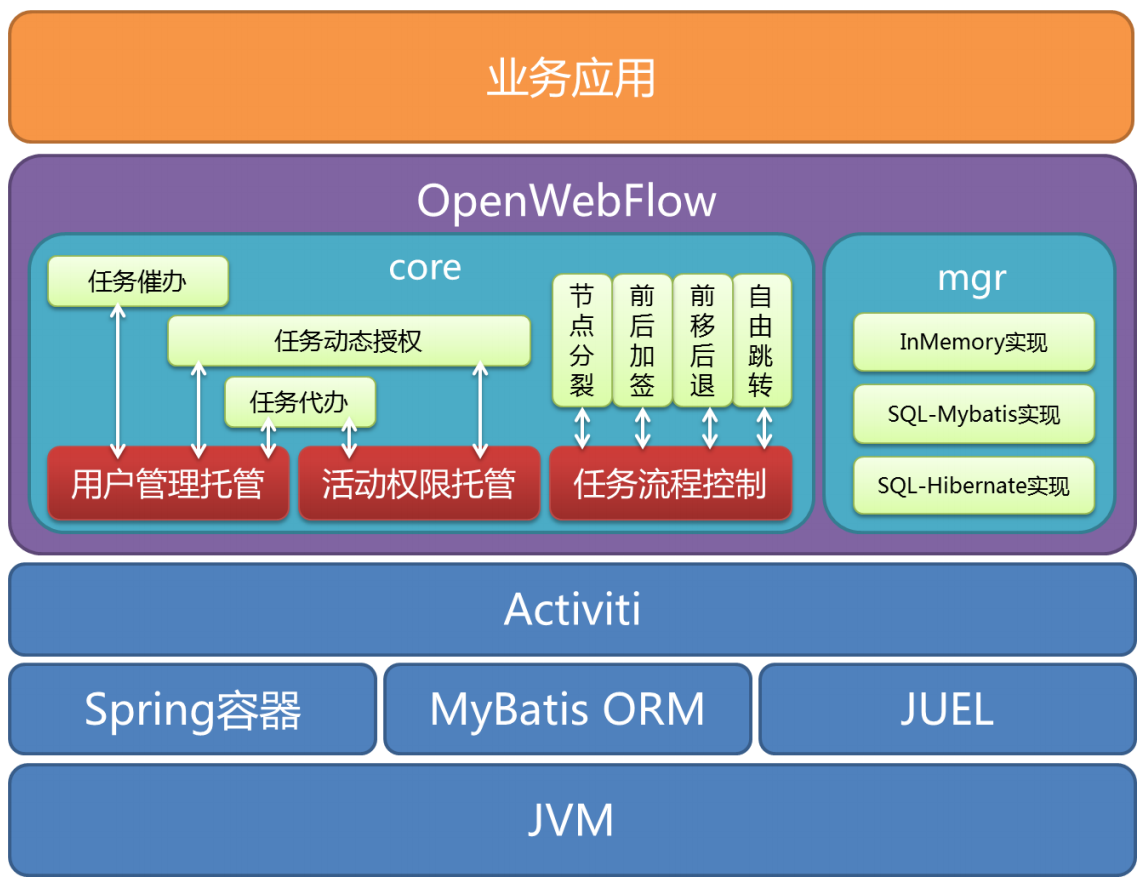
OpenWebFlow是基于Activiti(官方网站http://activiti.org/,代码托管在https://github.com/Activiti/Activiti)扩展的工作流引擎,它扩展的功能包括:
- 完全接管了Activiti对活动(activity)权限的管理。Activiti允许在设计model的时候指定每个活动的执行权限,但是,业务系统可能需要根据实际情况动态设置这些任务的执行权限(如:动态的Group)。OpenWebFlow完全实现了与流程定义时期的解耦,即用户对活动的访问控制信息单独管理(而不是在流程定义中预先写死),这样有利于动态调整权限,详见自定义活动权限管理;
- 完全接管了Activiti对用户表(IDENTITY_XXX表)的管理。在标准的工作流定义中,每个节点可以指定其候选人和候选用户组,但是比较惨的是,Activiti绑架了用户信息表的设计!这个是真正致命的,因为几乎每个业务系统都会属于自己的用户信息结构(包括User/Group/Membership),但不一定它存储在Activiti喜欢的那个库中,表的结构也不一定一样,有的时候,某些信息(如:动态的Group)压根儿就不采用表来存储。OpenWebFlow剥离了用户信息表的统一管理,客户程序可以忘掉Activiti的用户表、群组表、成员关系表,详见自定义用户成员关系管理;
- 允许运行时定义activity!彻底满足“中国特色”,并提供了安全的(同时也是优雅的)催办、代办、加签(包括前加签/后加签)、自由跳转(包括前进/后)、分裂节点等功能;
PiFlow
![]()






πFlow is an easy to use, powerful big data pipeline system. Try with: http://piflow.cstcloud.cn/piflow-web/
*Features
- Easy to use
- provide a WYSIWYG web interface to configure data flow
- monitor data flow status
- check the logs of data flow
- provide checkpoints
- Strong scalability:
- Support customized development of data processing components
- Superior performance
- based on distributed computing engine Spark
- Powerful
- 100+ data processing components available
- include spark、mllib、hadoop、hive、hbase、solr、redis、memcache、elasticSearch、jdbc、mongodb、http、ftp、xml、csv、json,etc.
